

煙業智匯

零售戶在線

微薰

手機版
煙業智匯
零售戶在線
微薰
手機版
【背景和目的】大語言模型(LLMs)在企業的應用正從通用能力展示轉向深度業務融合。然而,在算力、預算與人才受限的環境下,最大化輕量級模型(如7B及以下)的效能成為關鍵挑戰。傳統提示詞工程依賴靜態模板或專家手工設計,難以應對企業動態、復雜的任務需求。為突破此瓶頸,本文提出了一種提示詞工程的新范式:提示詞即時生成(Prompt-on-the-Fly Generation)。
【方法】該范式通過一個基于超自動化(Hyperautomation)理念構建的多階段、并行處理的工作流,為每一次任務動態生成一個高度結構化、富含深度上下文的系統提示詞。該工作流程序化地融合企業內部知識庫、用戶動態輸入乃至外部實時數據等多源異構信息,為輕量級模型構建了一個“即時認知環境”,引導其完成超越自身參數規模的復雜推理與生成任務。
【結果】實驗證明,該框架在1.8B和7B模型上均取得了顯著的性能提升,輸出準確率最高可達92%,用戶滿意度相較于基線提升超過140%。
【結論】本研究不僅提供了一套技術方案,更提煉出一種可復用的AI應用設計元模板(Meta-Template),為資源受限企業開辟了一條可行的、高效的AI生產力轉化路徑。
引言:
大語言模型(LLMs)的出現為企業自動化和智能化轉型注入了新的活力。然而,在資源相對匱乏的企業(如筆者所在的傳統行業的某煙草行業地市級商業公司),將這項技術投入真實商業環境面臨著獨特挑戰。這些企業的IT部門通常以業務支撐和系統運維為核心,缺乏專門的算法團隊與大規模AI模型訓練、微調的經驗。因此,采用輕量級、可私有化部署的開源模型(如參數規模在7B及以下)成為一種務實選擇。如何在不進行復雜模型改造的前提下,通過外部工程化的手段,挖掘并提升這些模型的潛力,使其勝任復雜的業務任務,成為一個亟待解決的核心問題。
提示詞工程(Prompt Engineering)作為一種低成本、高靈活性的模型優化技術備受關注[5-6, 18]。當前主流方法可歸為兩類:
1.手工專家調優:依賴個人經驗,效率低下、成本高昂,難以規模化復制。
2.靜態框架與模塊化組裝:通過預定義模塊進行拼接,如CRISPE等框架雖提供了結構化指導[7],但其“靜態組裝”的本質無法應對企業千變萬化、高度動態的業務場景,也難以充分利用企業沉淀的海量、多源的知識資產。
同時,在更廣闊的自動化提示詞工程領域,諸如“自動提示工程師”(Automatic Prompt Engineer, APE)[14]等研究側重于算法化生成提示詞的措辭,而以檢索增強生成(Retrieval-Augmented Generation, RAG)為代表的方法[3, 22]及其多種變體則聚焦于優化檢索內容的相關性。盡管這些技術通過引入少樣本(Few-shot)示例[1]或思維鏈(Chain-of-Thought, CoT)[2]等方式提升了模型性能,但它們通常優化的是單一環節,較少系統性地探討如何將多源、異構的企業內部上下文(如組織結構、崗位職責、階段性目標)與任務流程進行深度、自動化的編排。這些方法的共同局限在于,仍將提示詞視為一個“待設計”或“待填充”的靜態對象,在處理需要深度上下文理解和復雜邏輯推理的企業級任務時往往力不從心。
針對上述挑戰,本文提出了一種系統性的范式演進:從“靜態組裝”提示詞,躍遷到“動態生成”高度上下文感知的提示詞。我們不再將提示詞視為預設模板,而是將其看作一個應需而生的、由智能化流程即時創造的“信息包”。
本文的主要貢獻如下:
1.提出了一種提示詞工程新范式:以“提示詞即時生成”(Prompt-on-the-Fly Generation)為核心,旨在為每一次任務動態構建最優的指令上下文,突破靜態方法的局限。
2.設計并實現了一個基于超自動化理念的動態上下文融合工作流。該工作流能夠將用戶結構化輸入、內部知識庫、場景化范例(Few-shot)[1]、推理路徑(CoT)[2]以及外部實時信息等異構數據源進行無縫融合與智能編排。
3.提煉并驗證了一種可復用的AI應用設計元模板(Meta-Template)。通過實驗證明,該框架能顯著提升輕量級模型的輸出質量,其核心設計思想可遷移至不同業務領域,為業務專家與IT人員協作開發AI應用提供了有效的方法論。
1 框架設計
1.1 設計思想
本框架的設計思想完全不同于傳統的模塊化拼接理念,它建立在四個全新的核心原則之上:
1.上下文至上 (Context is King):決定模型輸出質量的根本因素,是為其提供的上下文的深度、廣度和相關性。框架的首要目標是為模型構建一個豐富、精確、多維度的“認知環境”。
2.流程即智能 (Process as Intelligence):智能不應僅被視為模型內部的黑箱能力。我們主張,數據在系統中的流轉、處理與融合的流程本身,就是一種更高維度的、可設計的智能。這正是超自動化(Hyperautomation)理念的體現,即通過協同多種技術(LLM節點、知識庫、解析器等)來智能地自動化端到端的業務流程。
3.動態生成 (On-the-Fly Generation):放棄“一詞多用”的模板庫思想。最優的提示詞是為特定任務即時生成的、一次性的。它由自動化工作流在用戶需求的驅動下實時創造,而非從靜態庫中調用。
4.多源融合 (Multi-Source Fusion):框架的核心能力在于打破企業內部的知識孤島,將結構化、非結構化、內部、外部的各類信息無縫地、自動化地融合到提示詞的構建過程中。
1.2 體系架構
基于上述思想,我們構建了一個以“超自動化工作流引擎”為核心的體系架構。該引擎(本文基于開源平臺Dify實現,但架構本身具有平臺無關性)作為系統的“大腦”,負責調度各類工具和LLM節點,執行數據融合與提煉,最終動態生成提示詞。

圖1 基于超自動化工作流的提示詞工程體系架構
1.3? 核心工作流詳解
本框架的核心是一個包含五個階段、內部并行處理的復雜工作流,旨在實現提示詞上下文的極致豐富與精準。
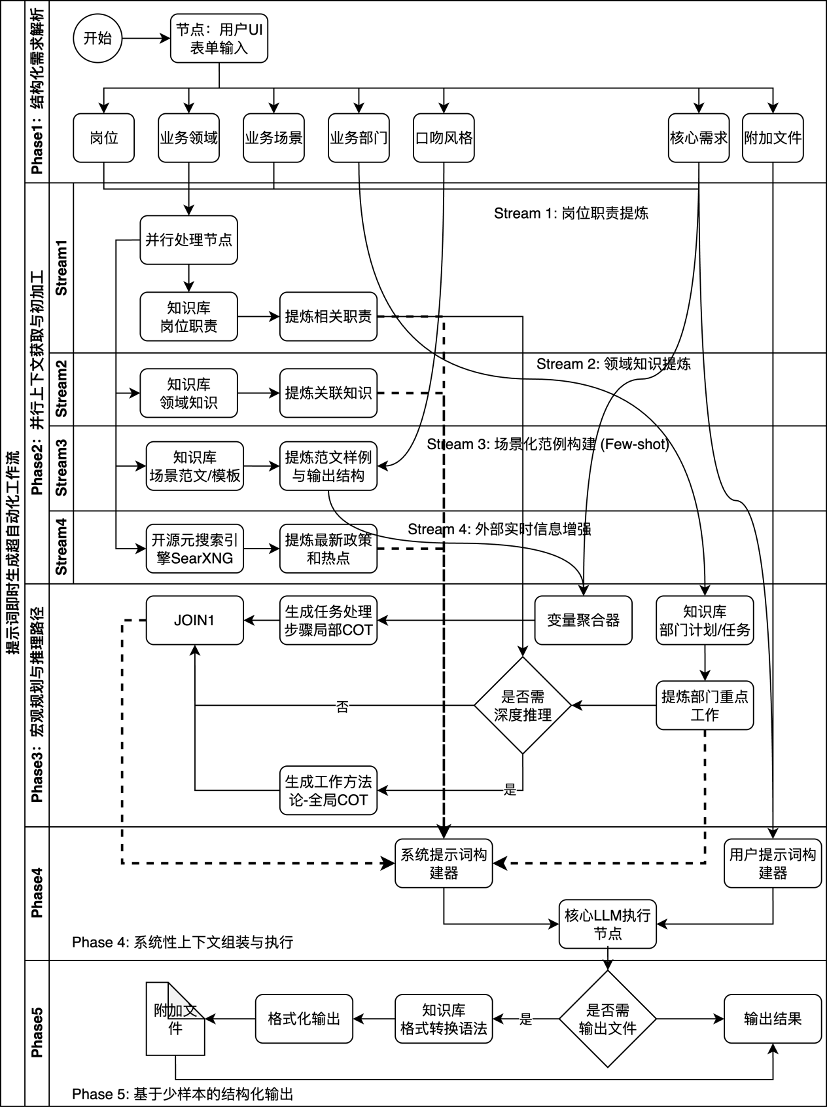
圖2 提示詞即時生成超自動化工作流
工作流階段詳解:
階段一:結構化需求解析:用戶通過UI表單將模糊的業務意圖轉化為多維度的結構化輸入。
階段二:并行上下文獲取與初加工:工作流并行啟動四個子流,高效地從知識庫和互聯網中抓取與崗位、領域、場景范例和外部熱點相關的信息,并進行初步提煉。
階段三:宏觀規劃與推理路徑構建 (CoT):此階段是賦予模型“思考能力”的關鍵。工作流結合微觀的任務步驟(局部CoT)和宏觀的部門計劃、工作方法論(全局CoT),為模型提供從戰術到戰略的完整思考框架。
階段四:系統性上下文組裝與執行:將前序所有階段提煉出的上下文信息全部聚合,形成一個包含多源信息、結構化的系統提示詞 (System Prompt),為模型預設一個詳盡的“虛擬專家”人格和知識背景。同時,將用戶原始需求構造成用戶提示詞 (User Prompt),一同送入核心LLM執行。
階段五:基于少樣本的結構化輸出:根據需要,從知識庫檢索格式化語法作為少樣本示例,引導模型生成符合業務規范的、即所得的最終交付物。
2 實驗設計與結果分析
2.1 實驗設置
1.任務集
核心任務:生成一份專業的煙草市場分析報告。
泛化任務:生成Python API調用代碼、生成客服標準回復。
2.模型與平臺
模型:Qwen-1.8B, Qwen-7B, Mistral-7B-Instruct-v0.2。
平臺:Dify。
3.對比策略
傳統提示詞 (Baseline):模擬普通用戶輸入的簡單指令。
靜態模板提示詞 (Static Template):使用預設模板。
標準RAG框架 (Standard RAG):基礎的檢索增強生成。
本文框架 (Our Framework):基于超自動化工作流的動態生成提示詞。
4.評估:由50名終端用戶和15名領域專家組成的混合小組進行雙盲評估,并對評分結果進行配對樣本t檢驗和效應大小(Cohen's d)分析。
2.2 主要實驗:市場分析報告生成任務
表1 不同策略在“市場分析報告”任務上的性能對比

結果分析:本文框架在所有維度上均顯著優于其他策略(p < 0.01),且效應大小值(Cohen's d > 2.0)表明這種優勢在實踐中具有重大意義。以Qwen-7B為例,用戶滿意度相對增幅高達140.4%。與RAG對比尤為關鍵:RAG能找到原始數據,但在業務邏輯和結構上表現差。這證明,對于需要深度結構化和強邏輯推理的企業任務,一個精心編排、融合了領域方法論的確定性工作流,是穩定產出專家級內容的關鍵。
2.3 消融實驗:探究框架組件的有效性
表2 本文框架(基于Qwen-7B)在核心任務上的消融實驗結果

結果分析:消融實驗清晰地揭示了框架的內部價值構成:1)內部知識庫是基石;2)CoT是邏輯的靈魂;3)Few-shot是結構的骨架。這證明了框架的成功源于多組件的協同效應,而非單一元素的簡單疊加。
2.4 泛化能力測試
我們將為市場分析報告設計的工作流“元模板”,經過少量適配,應用到了技術和客服兩個全新領域,同樣取得了顯著的性能提升(代碼正確率從45.5%提升至89.6%,客服回復準確性從60.3%提升至94.7%)。這驗證了本框架所蘊含的方法論具有高度的可遷移性。
3 討論
3.1 框架價值
1.從“賦能”到“賦魂”:傳統RAG是給模型“賦能”——給予知識。本框架通過融入崗位職責、領域方法論(CoT)、部門計劃等,為模型“賦魂”——構建一個具備專家心智模型的“數字員工”。消融實驗證明,正是這種深度的上下文融合帶來了性能的質變。
2.確定性流程駕馭不確定性模型:與Agent的自由探索相比,本框架的超自動化工作流代表了一種“確定性智能”。在規則明確的企業級任務中,這種確定性流程能有效引導大模型,確保輸出的穩定性、可靠性和專業性。
3.知識資產的協同效應:框架的能力上限來自于各個信息源的協同效應(Synergy)。是崗位職責定義“我是誰”,領域知識告知“我知道什么”,CoT指明“我該怎么想”,場景范例展示“我該怎么做”,它們在工作流的編排下形成了1+1>2的增強效果。
4.提供可復用的設計元模板:本研究的核心產出不僅是一個具體的工作流,更是一種可被復用的“工作流設計元模板”。它降低了業務人員應用AI的門檻,使AI應用開發更像是一個業務流程優化項目。業務專家可以將他們的隱性知識和判斷邏輯,通過這個元模板“翻譯”成高效的AI工作流。
3.2 挑戰與展望
工作流的生命周期管理:初期設計需要業務與技術團隊深度協作,且隨著業務變化,工作流需要持續地維護與迭代,這對傳統IT團隊提出了新的要求。
對知識庫質量的高度依賴:框架的輸出上限取決于輸入知識庫的質量。建立一套完善的企業知識治理和持續更新機制是成功的關鍵前提。
未來方向:可探索將此框架與更復雜的Multi-Agent系統結合,由超自動化工作流擔任“指揮官”角色,編排多個專用Agent協同完成更宏大的任務。同時,研究如何利用AI自動優化和生成工作流本身,將是降低應用門檻的下一步關鍵。
4 結論
本文針對資源受限企業在應用大語言模型時面臨的困境,提出了一種從“靜態組裝”轉向“動態生成”的提示詞工程新范式。通過設計并實現一個基于超自動化理念的智能工作流,我們為輕量級模型即時構建了深度定制的認知上下文。實驗結果表明,該框架顯著增強了輕量級模型的任務完成質量和邏輯推理能力,使其在特定業務場景下能夠媲美大型模型的表現。本研究為企業如何低成本、高效率地將AI技術與核心業務深度融合,提供了一套經過驗證、可遷移、可落地的系統性解決方案和設計思想。
參考文獻
[1] Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners. In *Advances in Neural Information Processing Systems, 33*, 1877-1901.
[2] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E., Le, Q., & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. In *Advances in Neural Information Processing Systems, 35*, 24824-24837.
[3] Lewis, P., Pérez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., ... & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. In *Advances in Neural Information Processing Systems, 33*, 9459-9474.
[4] Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). ReAct: Synergizing reasoning and acting in language models. *arXiv preprint arXiv:2210.03629*.
[5] Sahoo, P., Singh, A. K., Saha, S., Jain, V., Mondal, S., & Chadha, A. (2024). A systematic survey of prompt engineering in large language models: Techniques and applications. *ACM Computing Surveys, 56*(9), 1-38.
[6] Schulhoff, S., Ilie, M., Balepur, N., Hug, K., McKane, A., Yan, L., ... & Resnik, P. (2024). The prompt report: A systematic survey of prompting techniques. *arXiv preprint arXiv:2406.06608*.
[7] White, J., Fu, Q., Hays, S., Sandborn, M., Olea, C., Gilbert, H., ... & Schmidt, D. C. (2023). A prompt pattern catalog to enhance prompt engineering with ChatGPT. *arXiv preprint arXiv:2302.11382*.
[8] Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T. L., Cao, Y., & Narasimhan, K. (2023). Tree of thoughts: Deliberate problem solving with large language models. *arXiv preprint arXiv:2305.10601*.
[9] Yao, Y., & Li, Z. (2023). Beyond chain-of-thought, effective graph-of-thought reasoning in large language models. *arXiv preprint arXiv:2305.16582*.
[10]? Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., & Zhou, D. (2022). Self-consistency improves chain of thought reasoning in language models. *arXiv preprint arXiv:2203.11171*.
[11]? Dhuliawala, S., Komeili, M., Xu, J., Raileanu, R., Li, X., Celikyilmaz, A., & Weston, J. (2023). Chain-of-verification reduces hallucination in large language models. *arXiv preprint arXiv:2309.11495*.
[12]? Wang, B., Ping, H., Xu, M., Min, J., Li, Y., Hu, Y., ... & Chen, M. (2024). Chain-of-table: Evolving tables in the reasoning chain for table understanding. In *Proceedings of the AAAI Conference on Artificial Intelligence, 38*(17), 19138-19146.
[13] Asai, A., Wu, Z., Wang, Y., Sil, A., & Hajishirzi, H. (2023). Self-RAG: Learning to retrieve, generate, and critique through self-reflection. *arXiv preprint arXiv:2310.11511*.
[14]? Zhou, Y., Muresanu, A. I., Han, Z., Paster, K., Pitis, S., Chan, H., & Ba, J. (2022). Large language models are human-level prompt engineers. *arXiv preprint arXiv:2211.01910*.
[15]? Wang, L., Ma, C., Feng, X., Zhang, Z., Yang, H., Zhang, J., ... & Wang, X. (2023). A survey on large language model based autonomous agents. *arXiv preprint arXiv:2308.11432*.
[16]? Qin, Y., Patil, S. D., Gui, T., Lin, Y., Zhang, J., Qin, Y., ... & Nouriborji, M. (2023). ToolLLM: Facilitating large language models to master 16000+ real-world APIs. *arXiv preprint arXiv:2307.16789*.
[17]? Liu, Y., Yao, Y., Zhang, J., Gong, Y., Duan, T., Li, B., ... & Xiong, D. (2023). AgentBench: Evaluating LLMs as agents. *arXiv preprint arXiv:2308.03688*.
[18]? Liu, P., Yuan, W., Fu, J., Jiang, Z., Hayashi, H., & Neubig, G. (2023). Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. *ACM Computing Surveys, 55*(9), 1-35.
[19] Zaharia, M., Chen, A., Zou, J., & Stoica, I. (2023). Operationalizing large language models: An engineering view. *arXiv preprint arXiv:2311.08119*.
[20]? Tonmoy, S. M. T. I., Zaman, S. M. M., Phan, V., Krishnamurthy, P., Domeniconi, C., & Evans, D. (2024). A comprehensive survey of hallucination mitigation techniques in large language models. *arXiv preprint arXiv:2401.01313*.
[21]? Liu, Y., Zhang, S., Zhang, S., Gong, C., Wang, J., Pang, K., ... & Wu, L. (2023). A survey of large language models for healthcare: From data, technology, and applications to accountability and ethics. *Meta-Radiology, 1*(3), 100047.
[22]? Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., ... & Sun, K. (2023). Retrieval-augmented generation for large language models: A survey. *arXiv preprint arXiv:2312.10997*.
原創聲明:本文系煙草在線用戶原創,所有觀點、分析及結論均代表作者個人立場,與本平臺及其他關聯機構無關。文中內容僅供讀者參考交流,不構成任何形式的決策建議或專業指導。本平臺不對因依賴本文信息而產生的任何直接或間接后果承擔責任。
版權聲明:未經作者書面明確授權,任何單位或個人不得以任何形式(包括但不限于全文/部分轉載、摘編、復制、傳播或建立鏡像)使用本文內容。若需轉載或引用,請提前聯系煙小蜜客服(微信號tobacco_yczx)獲得許可,同時注明作者姓名及原文出處。違反上述聲明者,作者將依法追究其法律責任。

2025中國雪茄(四川)博覽會暨第七屆“中國雪茄之都”全球推介之旅


